
値段が2倍になっても、それでも買う理由
APIの料金が前モデルの2倍になった。それなのにOpenAIはこのモデルを「むしろお得」と言い切ります。普通なら失笑を買いそうなこの主張、実際に中身を見てみると、単なる強がりでは片付けられない部分があります。
4月24日に発表されたGPT-5.5は、OpenAIが「新しいクラスのインテリジェンス」と呼ぶエージェント型モデルです。入力トークン100万件あたり5ドル、出力は30ドルで、前モデルGPT-5.4のそれぞれ2.50ドル、15ドルからきっちり2倍に跳ね上がりました。ところが同社は、同じタスクをこなすのに必要なトークン数が大幅に減るため、実質的なコストは据え置きに近いと主張しています。これが本当かどうか、開発者たちが実地で検証するのはこれからです。
ベンチマークで見えた「強さ」と「穴」
エージェント型コーディングの評価指標であるTerminal-Bench 2.0で、GPT-5.5は82.7%を記録しました。AnthropicのClaude Opus 4.7が69.4%、GoogleのGemini 3.1 Proが68.5%ですから、差は13ポイント以上あります。難度の高い数学問題を扱うFrontierMath Tier 4では35.4%で、Claude Opus 4.7の22.9%、Gemini 3.1 Proの16.7%を大きく上回っています。
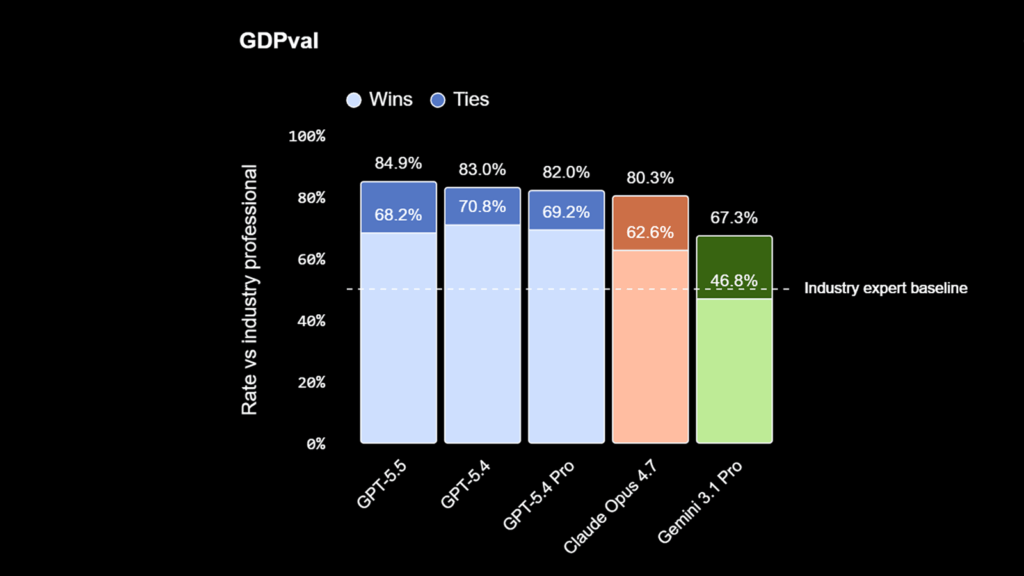
ただし、全ての指標でトップではありません。GitHubの実際の課題解決を評価するSWE-Bench Proでは、Claude Opus 4.7が64.3%に対しGPT-5.5は58.6%と負けています。ツール活用能力を測るMCP Atlasでも、Claude Opus 4.7(79.1%)とGemini 3.1 Pro(78.2%)に75.3%で及びません。44職種にわたる実務タスクを評価するGDPvalは84.9%で、前モデルの83.0%からほぼ横ばいです。つまり、エージェントや数学領域での伸びは本物ですが、日常の幅広い業務での体感は劇的には変わらないかもしれません。
超長文コンテキストで起きた大きな飛躍
見逃しがちですが、長文処理の改善がこのモデルの隠れた目玉です。512Kから100万トークンという超長文での情報探索ベンチマークMRCR v2で、GPT-5.4が36.6%だったのに対しGPT-5.5は74.0%まで上昇しました。100万トークンを使ったGraphwalks BFSテストに至っては、9.4%から45.4%へと跳ね上がっています。
この改善は、コード解析や大規模ドキュメントの処理といった実務シナリオで効いてきます。GPT-5.5 Proはさらに上位で、BrowseCompウェブリサーチ評価で90.1%を記録しており、豊富なコンテキストを与えて使う「リサーチパートナー」的な使い方に向いていると、早期テスターたちは口を揃えます。
「スーパーアプリ」構想との接続
OpenAI共同創業者のグレッグ・ブロックマンは、GPT-5.5のリリースを「スーパーアプリ」実現に向けた一歩と位置づけました。ChatGPT、Codex、AIブラウザを一つのサービスに統合するという構想で、エンタープライズ向けに「何でもできるツール」を目指すものです。
Jakub Pachocki最高科学責任者の発言も興味深いものでした。「過去2年間の進化は、驚くほど遅かったと言っていい。中期的にはさらに大きな改善が待っている」。業界全体が加速するなか、今後のリリースペースが落ちる兆候は今のところ見当たりません。サイバーセキュリティ能力はPreparedness Frameworkで「High」評価を維持しており、検証済みのセキュリティ研究者向けに拡大アクセスプログラムも設けられています。GPT-5.5は単体の製品というより、OpenAIが描く次世代プラットフォームへの布石として見るほうが、その位置づけが正確に見えてきます。

