
コスト競争に殴り込みをかけた一手
性能が高ければ高いほど、費用もかさむ。AIモデルの世界ではそれが当たり前でした。ところがCursorが5月18日にリリースしたComposer 2.5は、その常識を静かに、しかし確実に揺さぶっています。
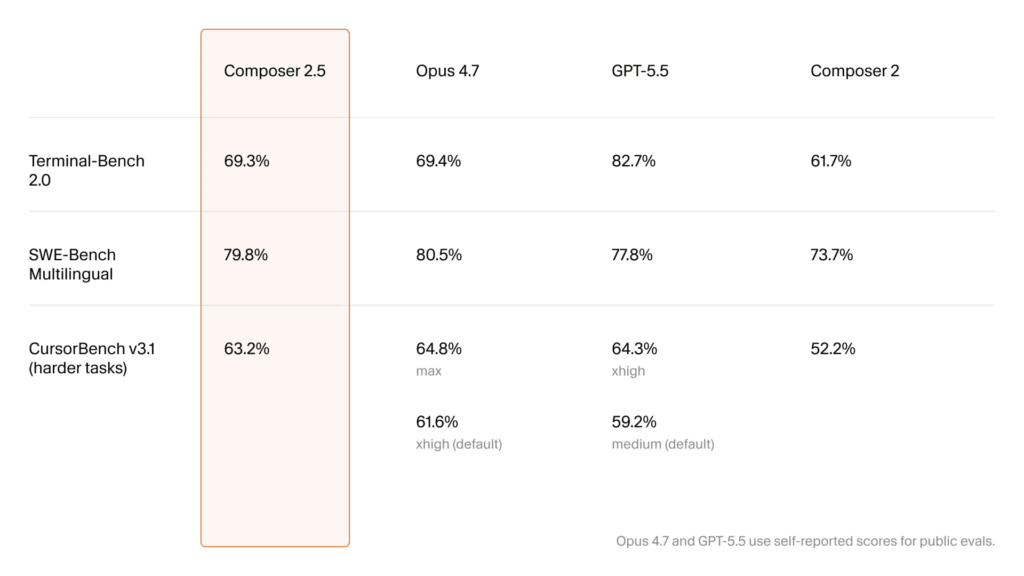
SWE-Bench MultilingualとCursorBench v3.1という2つの主要ベンチマークで、このモデルはAnthropicのClaude Opus 4.7やOpenAIのGPT-5.5と同水準のスコアを叩き出しました。前者で79.8%、後者で63.2%という数字は、業界トップクラスのモデルと肩を並べるものです。しかし本当に注目すべきはそこではありません。1タスクあたりのコストが競合の10分の1以下、場合によっては11ドルのところを1ドル未満で済むという点が、このリリースの核心です。
Kimi K2.5という土台と25倍の訓練量
Composer 2.5の出発点は、中国のスタートアップMoonshotが公開したオープンソースモデル「Kimi K2.5」のチェックポイントです。ここから先が興味深いところで、Cursorは前世代のComposer 2と比べて25倍もの合成タスクを使って追加訓練を行いました。しかもコンピュートの予算の85%を、追加訓練と強化学習に集中投下しています。
この配分の思い切り方は、モデルをゼロから作るよりも既存の良質な基盤を徹底的に鍛え上げる路線を選んだことを示しています。料金体系は通常版が入力100万トークンあたり0.50ドル、出力100万トークンあたり2.50ドル。速度優先の高速版でも同等の性能を持ちながら、入力3.00ドル・出力15.00ドルで利用できます。Opus 4.7やGPT-5.5の価格帯と比べれば、その差はあまりにも明確です。
次のモデルはSpaceXとxAIが絡む桁違いのスケール
Composer 2.5が本番稼働を始めた一方で、Cursorはすでに次世代モデルの訓練を進めています。SpaceXとxAIと共同で、100万基のH100相当GPU群から成る「Colossus-2」クラスターを使い、Composer 2.5の10倍のコンピュートをかけてゼロから構築するプロジェクトです。
同時期にSpaceXがCursorを600億ドルで買収する計画を発表していることも、この動きに重なります。コーディングAIのツールとして世界中の開発者に使われてきたCursorが、宇宙企業やAI企業を巻き込んだ巨大な技術投資の対象になっているという事実は、改めてこの市場の熱量を伝えています。
性能とコストの関係が変わりつつある
Composer 2.5が示したのは、最先端の性能は必ずしも最高額のモデルにしか宿らないという現実です。オープンソースの土台を活用し、訓練の比重を賢く偏らせることで、数千億円規模のリソースを持つ大手に並ぶスコアを出せる時代になりました。
開発者にとって現実的な問いは「どのモデルが最強か」ではなく「この性能をこのコストで使い続けられるか」に移っています。Composer 2.5はその問いに対して、少なくとも現時点では非常に説得力のある答えを持っています。次世代モデルが100万H100で何を見せてくるか、その前に今のComposer 2.5がどれだけ現場に浸透するかを見届けるだけでも、今年後半は目が離せません。

